Text Representation Basics for Natural Language Processing [Interactive Simulation]
![Text Representation Basics for Natural Language Processing [Interactive Simulation]](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1769996097089%2Fbe2ca449-7145-4a87-ae0b-c1ccd57960f2.webp&w=3840&q=75)
Mohamad's interest is in Programming (Mobile, Web, Database and Machine Learning). He is studying at the Center For Artificial Intelligence Technology (CAIT), Universiti Kebangsaan Malaysia (UKM).
[1] Introduction
Natural Language Processing (NLP) aims to enable computational systems to understand, analyze, and generate human language. A fundamental challenge in NLP lies in the representation of language in a form that machines can process effectively. The success of any NLP system depends heavily on how textual data is represented before modeling and analysis.
Text is not a flat or uniform object. Instead, it is naturally organized into multiple hierarchical levels, ranging from large collections of texts to smaller linguistic units. These levels include corpora, documents, sentences, words, and finally tokens, which serve as the computational units consumed by NLP algorithms.
This article presents a foundational overview of text representation in NLP, structured from the highest level of abstraction to the most granular.
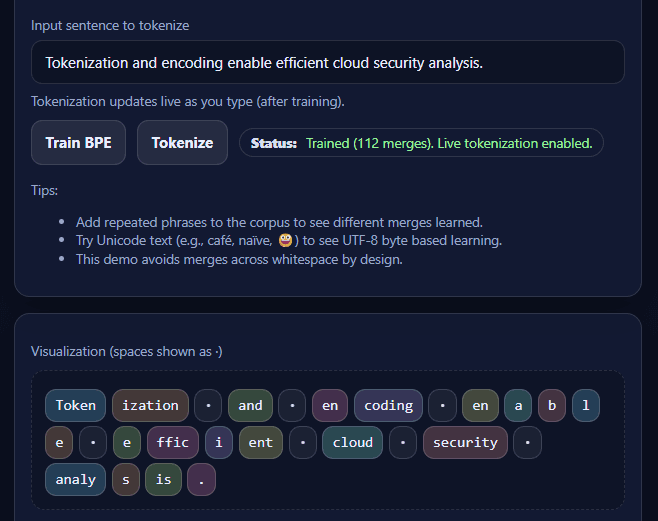
[2] Demo
[3] Corpus
A corpus is a structured collection of texts assembled for linguistic analysis or computational modeling. Corpora serve as the primary data source for NLP systems and are used to train, evaluate, and benchmark language models.
Corpora may consist of written text, spoken language transcripts, social media posts, or multimodal content. They can be monolingual or multilingual and may contain language variation such as dialects, informal usage, or code-switching. Because linguistic patterns vary significantly across contexts, corpus composition has a direct impact on the generalizability and fairness of NLP systems.
[4] Document
Within a corpus, a document represents an individual unit of text, such as an article, report, transcript, message, or post. Documents are typically treated as coherent units produced by a single author or speaker, often associated with metadata such as time, source, or author identity.
In NLP, documents often define the scope of analysis for tasks such as classification, information retrieval, topic modeling, and sentiment analysis.
[5] Sentence
A sentence is a smaller linguistic unit within a document, commonly associated with a complete thought or proposition. In written text, sentence boundaries are typically indicated by punctuation, while in spoken language they correspond more closely to utterances rather than strictly grammatical sentences.
Many NLP systems operate at the sentence level before aggregating results at the document or corpus level.
[6] Words
Traditionally, words are viewed as the fundamental building blocks of sentences. In corpus analysis, it is important to distinguish between word types and word instances. Word types refer to unique vocabulary items, while word instances refer to the total number of word occurrences. Vocabulary size grows continuously as corpus size increases, a phenomenon that poses challenges for computational models that rely on fixed vocabularies.
Because of these issues, word-based representations often suffer from sparsity and the presence of unseen or rare words. These limitations have motivated the shift toward subword-based approaches in modern NLP.
[7] Tokenization
Tokenization is the process of converting raw text into a sequence of tokens that serve as the input to NLP models. Tokens are not necessarily equivalent to words; they may correspond to words, subwords, characters, or even bytes, depending on the tokenization strategy employed.
Modern NLP systems may also rely on subword tokenization methods. By decomposing rare or unseen words into smaller, reusable units, subword tokenization addresses the unknown-word problem and enables models to generalize beyond their training data.
[8] Discussion
The progression from corpus to tokenization reflects a hierarchy of abstraction in text representation. Each level imposes structure on language data, enabling computational systems to manage linguistic complexity.
In modern NLP, this hierarchy is tightly integrated into end-to-end pipelines.
[9] Conclusion
Text representation forms the foundation of natural language processing. By organizing language data into a hierarchy of corpora, documents, sentences, words, and tokens, NLP systems transform raw text into structured input suitable for computational modeling. Each level introduces distinct challenges and design choices that directly influence system performance, robustness, and generalizability.
🤓
Appendix
[1] Speech and Language Processing. Daniel Jurafsky & James H. Martin
https://ontheline.trincoll.edu/images/bookdown/sample-local-pdf.pdf