1. Introduction
Modern natural language processing (NLP) systems do not operate directly on raw text. Instead, text must first be transformed into a structured representation that models can process efficiently. One of the most important steps in this transformation is tokenization, the process of breaking text into smaller units called tokens.
Early NLP systems often relied on word-level tokenization, where each distinct word is treated as an atomic unit. While simple, this approach suffers from several limitations, including large vocabularies, poor handling of rare or unseen words, and difficulties with morphologically rich languages. To address these issues, subword-based tokenization methods were introduced. Among them, Byte-Pair Encoding (BPE) has become one of the most influential and widely adopted techniques.
2. Motivation for Subword Tokenization
Word-level tokenization assumes that words are the smallest meaningful units. In practice, this assumption fails for several reasons:
Vocabulary Explosion
Real-world corpora contain millions of distinct word forms due to inflection, compounding, spelling variations, and domain-specific terms.
Out-of-Vocabulary (OOV) Words
New or rare words cannot be represented if they are not present in the predefined vocabulary.
Morphological Complexity
Many languages encode meaning through prefixes, suffixes, and stems that are shared across words.
Subword tokenization solves these problems by representing text as sequences of smaller units that can be recombined to form words. BPE is one of the earliest and most effective algorithms to implement this idea.
3. What Is Byte-Pair Encoding?
Byte-Pair Encoding is a data-driven, frequency-based tokenization algorithm that constructs a subword vocabulary by repeatedly merging the most frequent adjacent symbols in a corpus.
Originally developed as a data compression technique, BPE was later adapted for NLP to learn meaningful subword units automatically, without requiring linguistic rules or annotations.
In modern NLP, BPE typically operates at the byte or character level, allowing it to represent any text, including numbers, punctuation, and Unicode symbols.
4. The BPE Training Process
The BPE algorithm consists of a training phase followed by an encoding phase.
4.1 Initial Representation
Text is first broken into basic symbols. In byte-level BPE, each symbol corresponds to a UTF-8 byte. This guarantees that every possible character can be represented, regardless of language or script.
For example, a word is initially represented as a sequence of individual bytes.
4.2 Counting Adjacent Pairs
The algorithm scans the entire training corpus and counts how often each adjacent pair of symbols appears.
Example (conceptual):
Each pair is associated with a frequency count.
4.3 Merging the Most Frequent Pair
The most frequent adjacent pair is merged into a new symbol. This new symbol becomes part of the growing vocabulary.
For instance, if t + h occurs most frequently, it may be merged into a single token th.
4.4 Iterative Merging
The merge process is repeated a fixed number of times or until no frequent pairs remain. Each iteration increases the vocabulary size and creates larger subword units.
Over time, common words, prefixes, and suffixes naturally emerge as stable tokens.
5. Encoding New Text
Once the merge rules have been learned, they are applied deterministically to new input text.
The encoding process:
Converts input text into initial symbols (bytes or characters).
Applies the learned merge rules in the same order used during training.
Produces a sequence of subword tokens.
This ensures that the same text is always tokenized consistently, which is essential for reproducibility and model training.
6. Properties of BPE Tokenization
6.1 Open Vocabulary
Because BPE operates on bytes or characters, it can represent any input string without generating unknown tokens.
6.2 Frequency-Driven Units
Tokens correspond to patterns that occur frequently in the training corpus. Common words and morphemes become single tokens, while rare words are decomposed into smaller units.
6.3 Language-Agnostic
BPE does not rely on linguistic rules. It works equally well for different languages, scripts, and mixed-language text.
6.4 Deterministic and Efficient
Once trained, BPE tokenization is fast and deterministic, making it suitable for large-scale NLP systems.
7. Demo
7.1. Corpus Example:
Byte Pair Encoding is a tokenization method used in natural language processing.
Byte Pair Encoding learns frequent byte pairs and merges them repeatedly.
In cloud security research, tokenization helps encode malicious payloads.
Cloud-native malware exploits cloud infrastructure and cloud services.
Cloud security analysts study cloud logs, cloud traffic, and cloud threats.
Tokenization transforms text into tokens.
Tokens may represent words, subwords, or byte sequences.
Encoding text into tokens allows efficient storage and modeling.
Cyber threat analysis often involves malware detection and payload decoding.
Malware payloads may contain encoded strings, repeated patterns, and obfuscated data.
Repeated patterns help Byte Pair Encoding learn stable subword units.
Unicode examples: café naïve résumé señor 😀 😀 😀
Numbers and versions: version1 version2 version10 v1.0 v1.1 v1.2
7.2. Test Example 1:
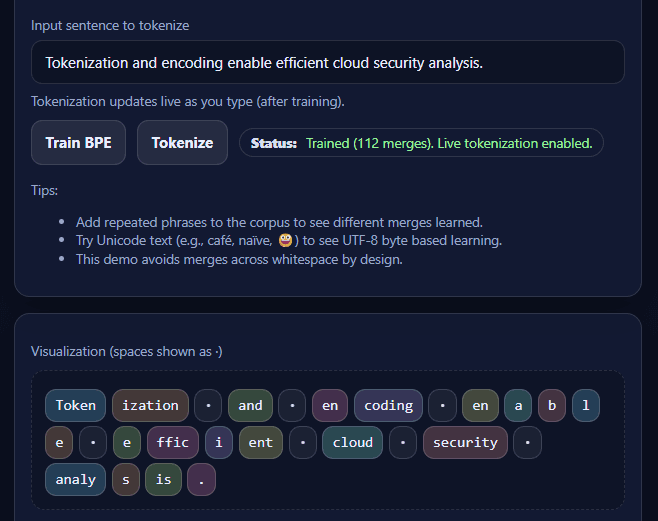
Tokenization and encoding enable efficient cloud security analysis.
7.3. Test Example 2 (Subword-heavy example):
Tokenization and encoding enable efficient cloud security analysis.
7.4. Test Example 3 (Unicode-focused):
Malware café payload naïve résumé 😀
7.5. Test Example 4 (Numeric / versioning):
cloud-security v1.2 tokenization version10 encoding
7.6. Test
8. Why BPE Is Widely Used in Modern NLP
BPE has become a foundational component in many transformer-based language models and NLP pipelines because it strikes a balance between:
Its simplicity, efficiency, and compatibility with neural models have made it a standard choice for text representation.
9. Interpreting BPE Through Visualization
When visualized, BPE tokenization reveals how text is gradually segmented into meaningful subword units. Common sequences appear as larger tokens, while less frequent patterns remain split.
Such visualizations help illustrate:
How repetition influences learned tokens
Why certain substrings are merged
How Unicode characters are handled at the byte level
These insights are especially valuable for teaching and debugging NLP systems.
10. Conclusion
Byte-Pair Encoding is a powerful and conceptually simple approach to subword tokenization. By learning frequent patterns directly from data, it avoids the limitations of word-level tokenization while remaining efficient and language-independent.
Understanding BPE is essential for anyone working with modern NLP models, as it forms the bridge between raw text and numerical representations used by machine learning systems. When paired with interactive visualizations, BPE becomes not only a practical tool but also an intuitive framework for understanding how machines process language.
🤓
Appendix
https://web.stanford.edu/~jurafsky/slp3/2.pdf
![Text Representation Basics for Natural Language Processing [Interactive Simulation]](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1769996097089%2Fbe2ca449-7145-4a87-ae0b-c1ccd57960f2.webp&w=3840&q=75)
